人工智能领域传来一则引人注目的消息。由前沿AI研究公司MosaicML发布的一项基准测试显示,通过其专有的软件栈进行深度优化后,AMD Instinct MI250加速卡在训练大型语言模型(如GPT-3级别)时的性能,可以达到业界标杆英伟达A100芯片的约80%。这一突破不仅为AI硬件市场注入了新的竞争活力,也凸显了专业化人工智能应用软件开发在释放硬件潜力、降低计算成本方面的关键作用。
硬件追赶与软件突围
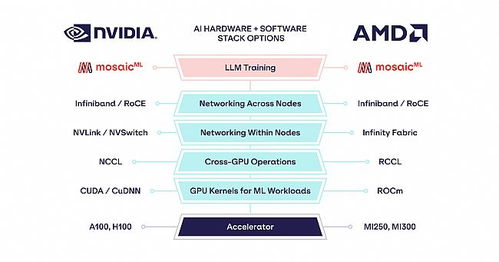
长期以来,英伟达凭借其强大的GPU硬件和成熟的CUDA软件生态,在AI训练与推理市场占据主导地位。AMD的MI250系列作为其挑战高端计算市场的重要产品,在纯硬件规格上(如HBM2e内存带宽、计算核心数量)已具备相当的竞争力。AI计算的效能并非仅由硬件参数决定,软件栈的成熟度、对流行AI框架(如PyTorch、TensorFlow)的优化支持,以及对特定计算模式(如混合精度训练、模型并行)的深度适配,才是将硬件算力转化为实际生产力的关键。
MosaicML的核心价值正在于此。该公司并非硬件制造商,而是一家专注于提供高效AI训练软件解决方案的开发商。其开发的软件工具链能够对训练过程进行全方位优化,包括:
- 算法优化:通过更高效的注意力机制实现、梯度压缩、动态批处理等技术,减少不必要的计算与通信开销。
- 系统级优化:深度优化针对AMD ROCm平台的底层内核,确保计算单元利用率最大化,并有效管理MI250芯片中独特的图形计算芯片(GCD)间通信。
- 流程自动化:提供简洁的API和自动化工具,让研究人员和工程师能更轻松地在AMD平台上部署和缩放大型模型训练任务,降低使用门槛。
正是这套高度专业化的软件方案,填补了AMD平台在高级AI工作负载上与传统CUDA生态之间的部分“软件鸿沟”,从而将MI250的潜在性能大幅释放出来,达到了对标A100的八成水平。
对AI应用开发的影响与意义
这一进展对广大人工智能应用软件的开发者与企业用户而言,意义深远:
1. 促进市场竞争,降低算力成本:更强大的替代方案出现,有助于打破算力市场的单一供应格局。从长期看,竞争的加剧将推动硬件价格趋于合理,并促使所有厂商(包括英伟达)持续创新,最终降低企业进行AI研发和部署的总体拥有成本(TCO)。
2. 提供更多元化的部署选择:对于受供应链、采购政策或技术战略影响,希望或需要使用AMD硬件的数据中心和企业来说,MosaicML的方案提供了一个性能可接受的可行路径。这使得AI应用软件的部署环境更加灵活多元。
3. 凸显软件定义AI基础设施的重要性:这一案例生动表明,在AI时代,软件已成为定义计算性能的核心要素之一。专注于算法、编译器、系统优化的软件公司,能够通过软硬件协同设计,显著提升现有硬件的实际效能。这激励更多开发者投身于底层AI软件工具的研发,推动整个产业生态的健康发展。
4. 加速AI普及化:更经济的算力选择,使得更多中小型研究机构、创业公司能够负担起大规模模型的训练与实验,有利于促进更广泛的AI创新和应用落地。
挑战与未来展望
达到“八成性能”是一个重要的里程碑,但前路依然充满挑战。英伟达的A100及其后续的H100芯片,在特定AI工作负载(尤其是推理和某些训练任务)上仍保持着领先优势,其庞大的CUDA软件生态和开发者社区依然是巨大的护城河。AMD与MosaicML等合作伙伴需要持续投入,扩大优化软件的支持范围(覆盖更多模型架构和任务),提升易用性和稳定性,并构建繁荣的开发者社区。
随着AMD新一代MI300系列等芯片的推出,以及MosaicML等软件公司优化技术的不断精进,AI计算市场的竞争必将更加激烈。这对于整个人工智能行业无疑是一大利好。它预示着,人工智能应用软件的开发将建立在更高效、更经济、更多样化的算力基础之上,从而加速智能技术向各行各业渗透,创造更大的社会与经济价值。