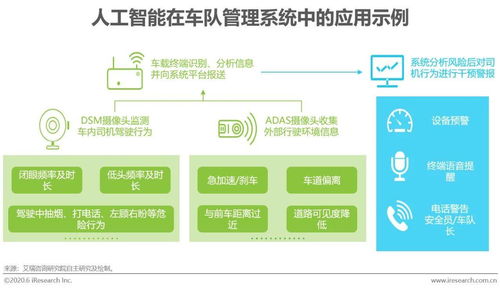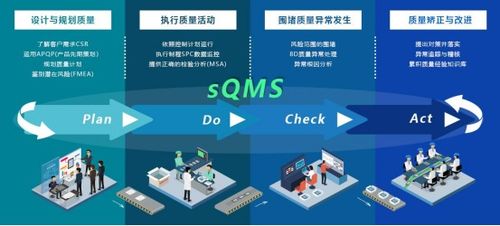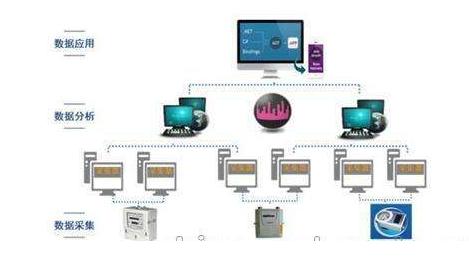
随着数字化转型浪潮席卷全球,数据已成为企业最核心的资产之一。海量数据的产生、流转与利用也带来了前所未有的挑战。在这一背景下,“数据复制”技术与人工智能(AI)的深度融合,正成为解锁数据潜能、驱动人工智能应用软件向更高级智能演进的关键引擎。这不仅让数据本身变得更“聪明”,更从根本上重塑了AI应用的开发范式与应用价值。
一、 数据复制:从静态备份到智能流动的基石
传统的数据复制技术主要服务于灾难恢复、备份和系统迁移,确保数据的可用性与一致性。但在AI时代,其内涵已极大拓展。现代数据复制解决方案能够实现跨云、跨地域、跨平台的数据实时或近实时同步,确保训练AI模型所需的高质量、高时效性数据流。
- 保障数据供给的“新鲜度”与一致性:AI模型,尤其是机器学习模型,其性能高度依赖于训练数据的质量和时效性。通过高效的数据复制,可以将业务系统产生的实时数据(如用户交互日志、物联网传感器数据、交易流水)近乎无延迟地同步到专门的数据湖、数据仓库或AI训练平台,确保模型能够基于最新、最全的数据进行学习和迭代,避免因数据陈旧导致的模型性能退化或决策偏差。
- 构建统一的“数据真相源”:在复杂的混合IT环境中,数据往往散落在多个孤立的系统中。智能数据复制能够将这些分散的数据汇聚到一个统一的、干净的“黄金副本”中,为AI模型提供一致、可信的数据基础,极大减少了数据清洗和预处理的工作量,提升了开发效率。
二、 AI赋能数据复制:让流程更智能、更高效
反过来,AI技术也正在深度改造数据复制过程本身,使其从一项依赖预设规则的“体力活”,升级为具备自适应、自优化能力的“智能体”。
- 智能调度与优化:AI算法可以分析数据访问模式、网络带宽状况和系统负载,动态调整数据复制的优先级、时间和带宽占用,在业务高峰时段减少影响,在空闲时段全力同步,实现资源利用最优化。
- 异常检测与自愈:利用机器学习模型,可以持续监控数据复制流水线的健康状况,自动识别传输延迟、数据不一致等异常模式,并预测潜在故障。在问题发生时,系统能够自动触发修复流程或切换到备用路径,保障数据流动的连续性与可靠性。
- 数据智能分层与迁移:结合数据热度和价值分析,AI可以自动将访问频繁的“热数据”复制到高性能存储,将历史“冷数据”迁移到低成本存储,并在需要时智能调度,从而在满足AI应用性能需求的显著降低总体存储成本。
三、 双轮驱动:加速人工智能应用软件开发与进化
数据复制与AI的结合,为人工智能应用软件的开发、部署和运维全生命周期注入了强大动力。
- 加速模型开发与训练周期:开发者无需等待漫长的数据整合周期。智能、连续的数据流为模型提供了源源不断的“燃料”,支持快速的实验、迭代和A/B测试,缩短了从概念验证到生产部署的路径。
- 赋能更复杂的应用场景:实时数据流与AI处理的结合,使得开发实时风险预警、个性化即时推荐、工业设备预测性维护等对时效性要求极高的应用成为可能。数据复制确保了分析引擎总能获取到最新的上下文信息。
- 简化分布式AI架构的管理:在边缘计算、多云AI训练等分布式场景中,智能数据复制是协调中心与边缘、云与云之间数据同步的核心枢纽,保障了分布式模型的协同训练与统一更新,降低了架构复杂性。
- 增强AI应用的可观测性与治理:通过复制AI模型生产环境中的输入输出数据、性能指标和日志,可以构建完整的模型行为追踪链路,便于进行模型效果评估、偏见检测、合规审计和持续优化,实现负责任的AI。
四、 未来展望:迈向自主的数据智能网络
数据复制与AI的融合将走向更深层次。我们有望看到一个“自主的数据智能网络”,其中数据复制不再是一个被动的传输过程,而是一个能主动理解数据内容、业务意图和应用需求的认知层。它可以自动为不同的AI工作负载准备、标注、增强和提供最合适的数据集,甚至在多个AI应用间智能地协调和共享数据价值,真正实现“让数据驱动数据,让智能孕育智能”。
###
“数据复制+AI”的组合,绝非两项技术的简单叠加,而是构建下一代智能数据基础设施的核心范式。它打破了数据流动的壁垒,赋予了数据自我管理和自我优化的能力,最终让人工智能应用软件变得更敏锐、更可靠、更富洞察力。对于致力于开发前沿AI应用的企业和开发者而言,积极拥抱这一趋势,构建智能化的数据流水线,无疑是在激烈竞争中抢占先机的关键一步。